접근
- length 로 2차원 배열(arr)을 초기화한다. snap_id 를 기억하는 변수를 지정한다. 차지하게 되는 총 메모리는 length + S (number of calls of set()) 이다.
- set 마다 해당 index 에 현재 snap_id 와 value 를 추가한다.
- 모든 range 내의 i에 대하여 arr[i] 는 오름차순으로 정렬되어있기에 get() 에서 bisect 로 적절한 snap_id 를 찾아 해당하는 value 를 리턴한다.
사고
처음에 이 코드로 냈는데 get과 set 모두 엉성하다.. bisect에 대한 예쁜 이해가 없어서 그렇다.
import bisect
class SnapshotArray:
arr = None
cnt = None
def __init__(self, length: int):
self.arr = [[[0, 0]] for i in range(length)]
self.cnt = 0
def set(self, index: int, val: int) -> None:
if self.arr[index][-1][0] == self.cnt:
self.arr[index][-1][1] = val
else:
self.arr[index].append([self.cnt, val])
def snap(self) -> int:
self.cnt += 1
return self.cnt - 1
def get(self, index: int, snap_id: int) -> int:
ans = bisect.bisect_left(self.arr[index], snap_id, key=lambda i: i[0])
if ans >= len(self.arr[index]):
return self.arr[index][-1][1]
elif self.arr[index][ans][0] > snap_id:
return self.arr[index][ans - 1][1]
else:
return self.arr[index][ans][1]
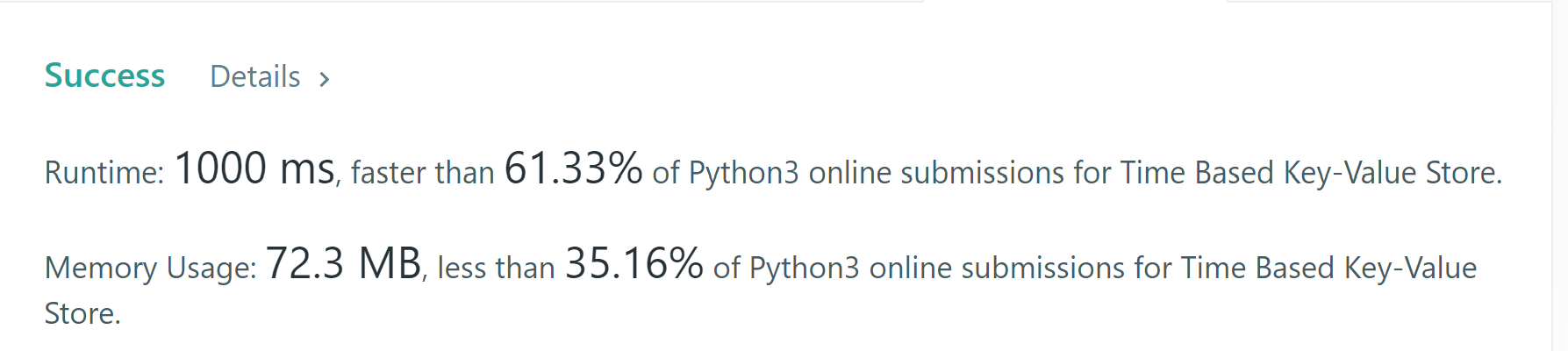
discussion 포럼에서 적절한 최적화를 발견했다. 근데 runtime 이 처음엔 차이가 나는게 이해가 안돼서 여러번 submit하니 차이가 없다. 경험상으로 leetcode runtime 환경이 좀 영향을 준다.
import bisect
class SnapshotArray:
arr = None
cnt = None
def __init__(self, length: int):
self.arr = [[[0, 0]] for i in range(length)]
self.cnt = 0
def set(self, index: int, val: int) -> None:
if self.arr[index][-1][0] == self.cnt:
self.arr[index][-1][1] = val
else:
self.arr[index].append([self.cnt, val])
def snap(self) -> int:
self.cnt += 1
return self.cnt - 1
def get(self, index: int, snap_id: int) -> int:
ans = bisect.bisect(self.arr[index], [snap_id + 1]) - 1
return self.arr[index][ans][-1]